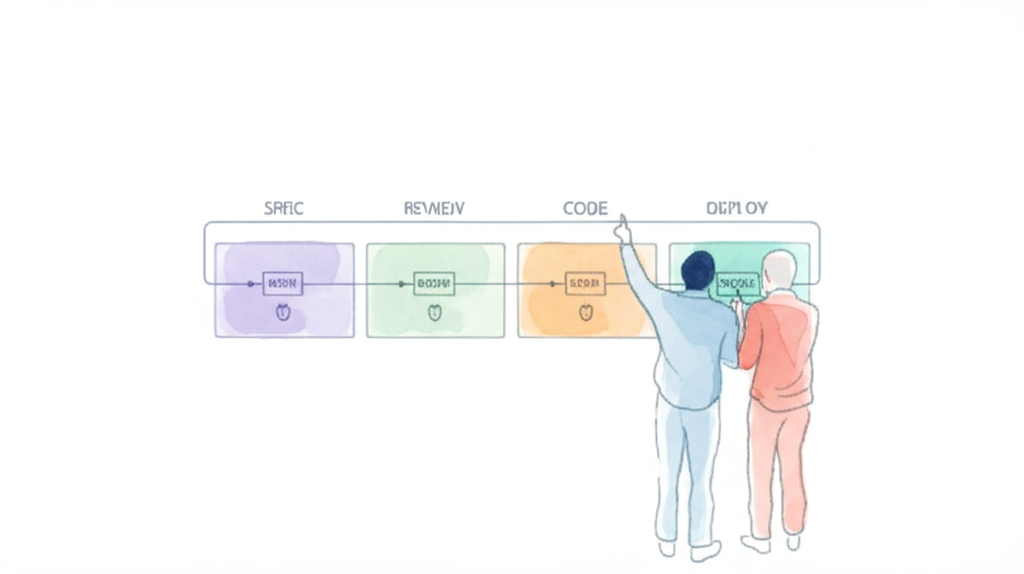
Developer does — task management & governance
→ Define tasks & sequence
→ Review & approve PRDs
→ Set coding rules & standards
→ UI design rules
→ Implementation rules
→ Define scoring rubrics
→ Configure model routing
→ Set evaluation criteria
→ Design agents & teams
→ Design AI skills
→ Edge case handling rules
→ Alignment & drift prevention
→ Security & perf standards
→ Pipeline optimization
→ Monitor gates, unblock STUCK
→ Optimize run cost (local / cloud LLMs)
Scale — 2–6 tasks · agent teams of 4
Each task runs with a team of 4 parallel agent workers in isolated environments. The developer manages the queue — reviewing gates when flagged, stopping misaligned runs, approving scope changes. Not writing code. Directing pipelines.
Automated: spec, tests, code, review, remediation, security, deployment