Insights › AI Development Pipelines
The 8 Stages of AI-Assisted Development
Most teams plateau at Stage 3. The ones that don’t, designed their way past it.
Where is your team right now?
3 questions · 20 seconds · Find your stage
How teams evolve
Every team follows the same trajectory
The specifics vary — different languages, stacks, org structures — but the pattern is remarkably consistent.
Autocomplete
A faster keyboard, not a different workflow

Writes code. Reviews AI suggestions line by line. Accepts or rejects. Full cognitive load remains with the developer.
Completes lines and functions based on context. Developer and AI operate at the same level — same task, same pace.
Automated: nothing
Prompted Changes
Output grows. Review burden grows with it.

Describes what needs changing. Reviews all output. Still owns every line — just writes fewer of them.
Rewrites functions, files, and components on instruction. Output volume grows. Review burden grows with it.
Automated: nothing
Collaborative Loop Most teams here
The ceiling is the developer’s attention bandwidth

Prompts brief → reviews PRD → approves approach → tests and debugs with AI. Conversational back-and-forth.
Drafts PRD → generates implementation → iterates on feedback. Developer is directing but still deeply involved in every decision.
Automated: some development. Review stays manual.
⚡ The Fork — After Stage 3
Two paths diverge here. The choice is architectural.
Both paths can run multiple tasks in parallel. Both use LLMs to generate code, write tests, and review output. The difference is who manages the workflow — and what happens when things go wrong.
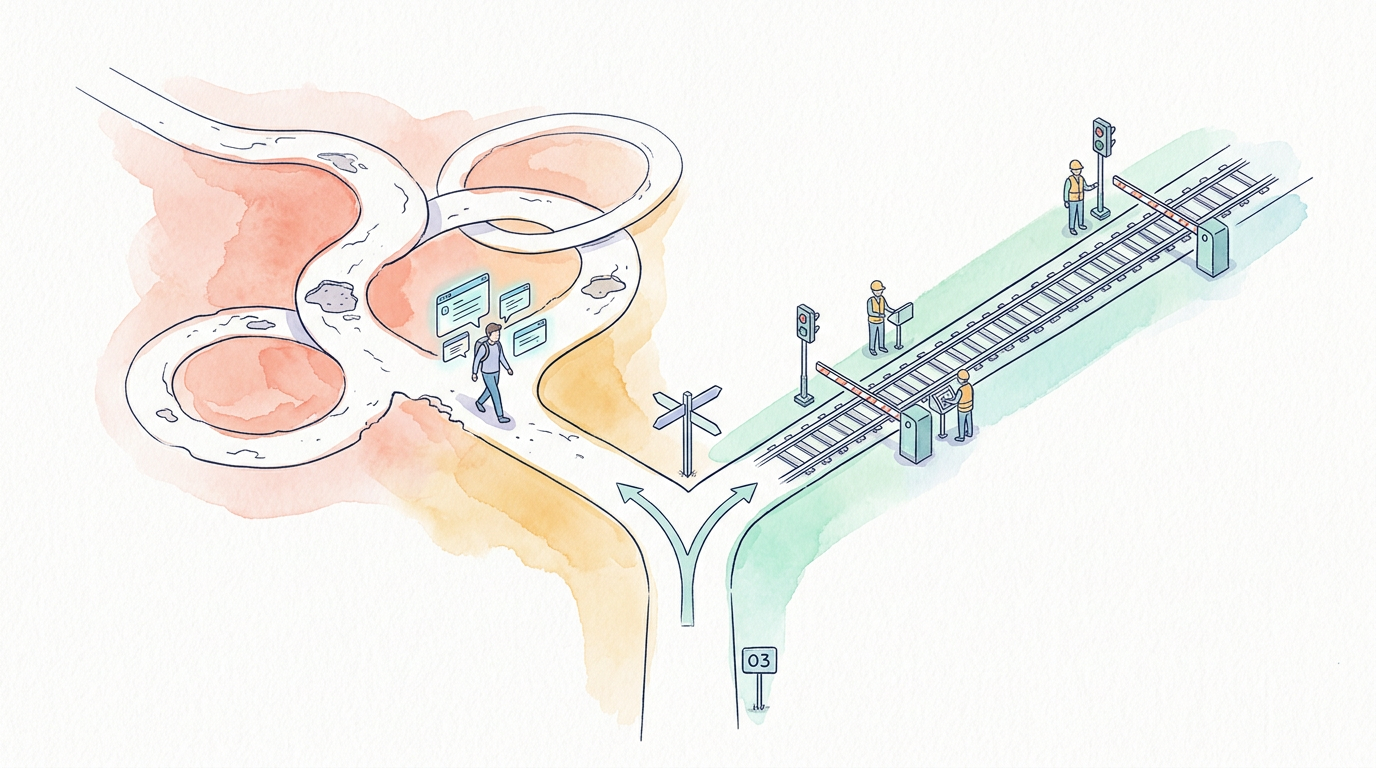
The LLM decides what to do next. It chooses which files to edit, which tests to run, and when to stop. The developer provides goals; the AI sequences the work. Powerful for exploration — but the workflow is only as reliable as the model’s judgment in that moment.
Scripts enforce the workflow. The LLM executes specific steps — generate code, write tests, review output — but never decides what comes next. Quality gates, circuit breakers, and adversarial reviews are structural, not optional. The pipeline is deterministic; only the content generation is probabilistic.
Point-by-point comparison
Where the architecture diverges in practice
| Path A: LLM-directed | Path B: Designed pipeline | |
|---|---|---|
| Execution & Control | ||
| Workflow control | LLM-directed sequencing | ✓ Script-enforced sequencing |
| Step skipping | Frequent step skipping (CodeRabbit) | ✓ Profile-enforced phases |
| Error loops | Unbounded retry cycles (DEV Community) | ✓ Deterministic circuit breakers |
| Quality & Review | ||
| Spec fidelity | Conversational interpretation | ✓ Formal acceptance criteria |
| Review quality | Self-review blind spots | ✓ Adversarial cross-review |
| Spec discipline | Optional | ✓ Non-negotiable (vague specs sent for remediation) |
| Reliability & State | ||
| State persistence | Context-window state | ✓ Disk-persisted checkpoints |
| Parallel tasks | Uncoordinated parallelism | ✓ Managed task isolation |
| Observability | Manual spot-checks | ✓ Continuous monitoring |
| Audit trail | Git commits only | ✓ Full provenance |
| Adoption & Cost | ||
| Setup cost | ✓ Zero upfront cost | Infrastructure required (AppliedMinds.ai) |
| Speed per task | ✓ Fast for simple work | Fixed overhead per task |
| Prototyping | Ideal for exploration | ✓ Lightweight profiles available |
| Maintenance | ✓ Nothing to maintain | Ongoing investment |
| Debugging | Manual and repetitive | ✓ Structurally reduced |
Both paths are productive. Path A is the right choice for prototyping, exploration, and one-off tasks. Path B is what you build when reliability, auditability, and team-scale operation matter. Most teams benefit from both — the question is which one is your default.
The foundation everything else depends on
Specs are where pipeline value is created — or destroyed
Every downstream failure — bad tests, wrong implementation, wasted review cycles — traces back to the spec. In LLM-directed workflows, specs are suggestions. In a designed pipeline, they’re contracts.
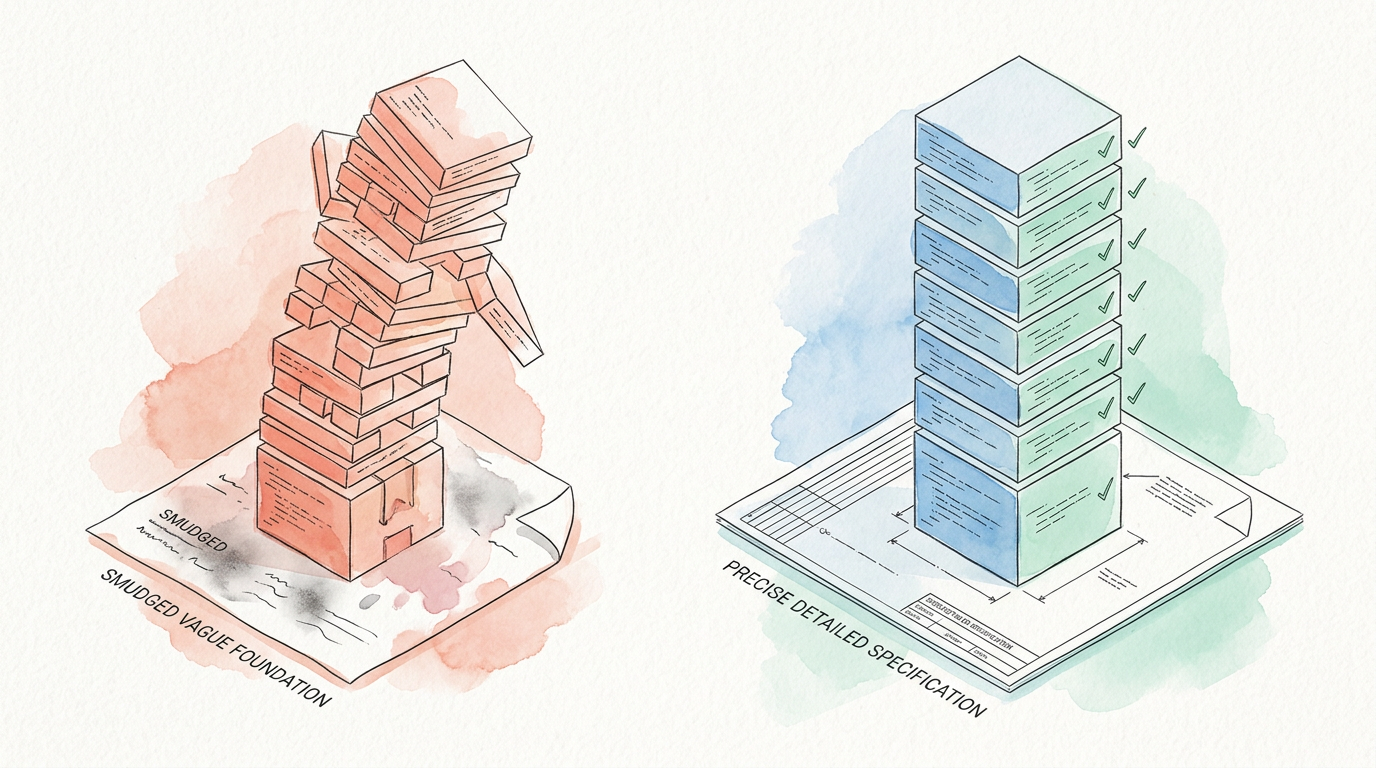
In our pipeline: The spec phase alone accounts for 2 review gates, an adversarial inquisitor pass, and mandatory remediation for vague acceptance criteria. This is where pipeline value is created — before a single line of code is generated.
Partial Pipeline
Some steps are automated. The gaps are where things break.

Configures pipeline steps. Monitors output. Intervenes when automation fails or produces off-spec results. Still owns integration.
Executes specific phases: generate code, run tests, basic review. But transitions between phases are manual or fragile.
Automated: code generation, test execution. Manual: review, integration, deployment.
Full Pipeline
Every step scripted. Every transition enforced. Every output reviewed.
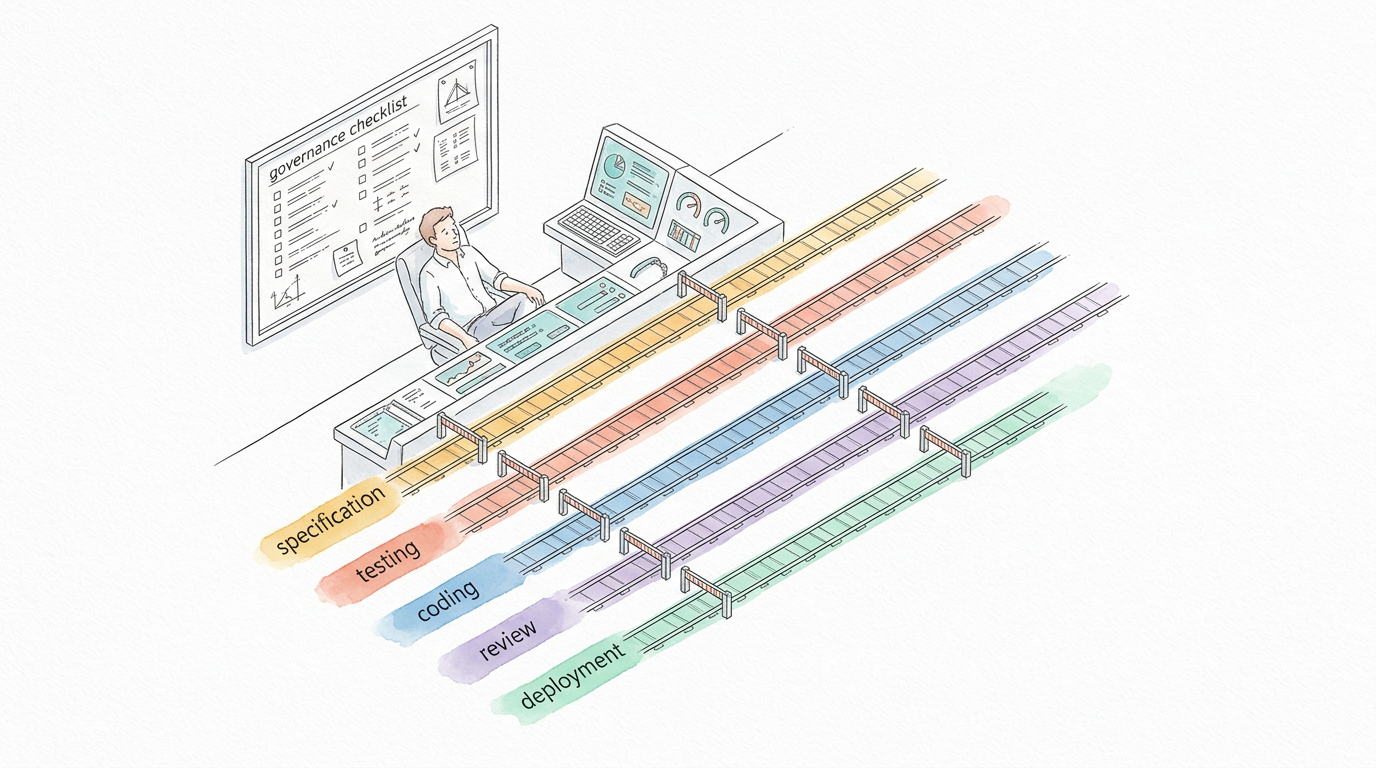
Writes specs. Reviews pipeline output. Makes architectural decisions. The pipeline handles everything else.
Executes the full TDD cycle: spec → red tests → green implementation → review → remediation. Each phase has quality gates.
Governance at every gate
- Spec review with adversarial inquisitor
- Red-phase test generation with acceptance criteria validation
- Green-phase implementation with circuit-breaker retry limits
- Implementation review against spec (not just “does it work”)
- Post-remediation gate before merge
- Continuous monitoring with stall detection
- Full provenance: every decision traced to a spec line
At this stage, the pipeline processes multiple tasks concurrently with full isolation. Each task follows the same deterministic path regardless of complexity.

Automated: everything except spec authoring and architectural decisions.
Configurable Pipeline
Same pipeline, different rigor levels. Context determines the profile.
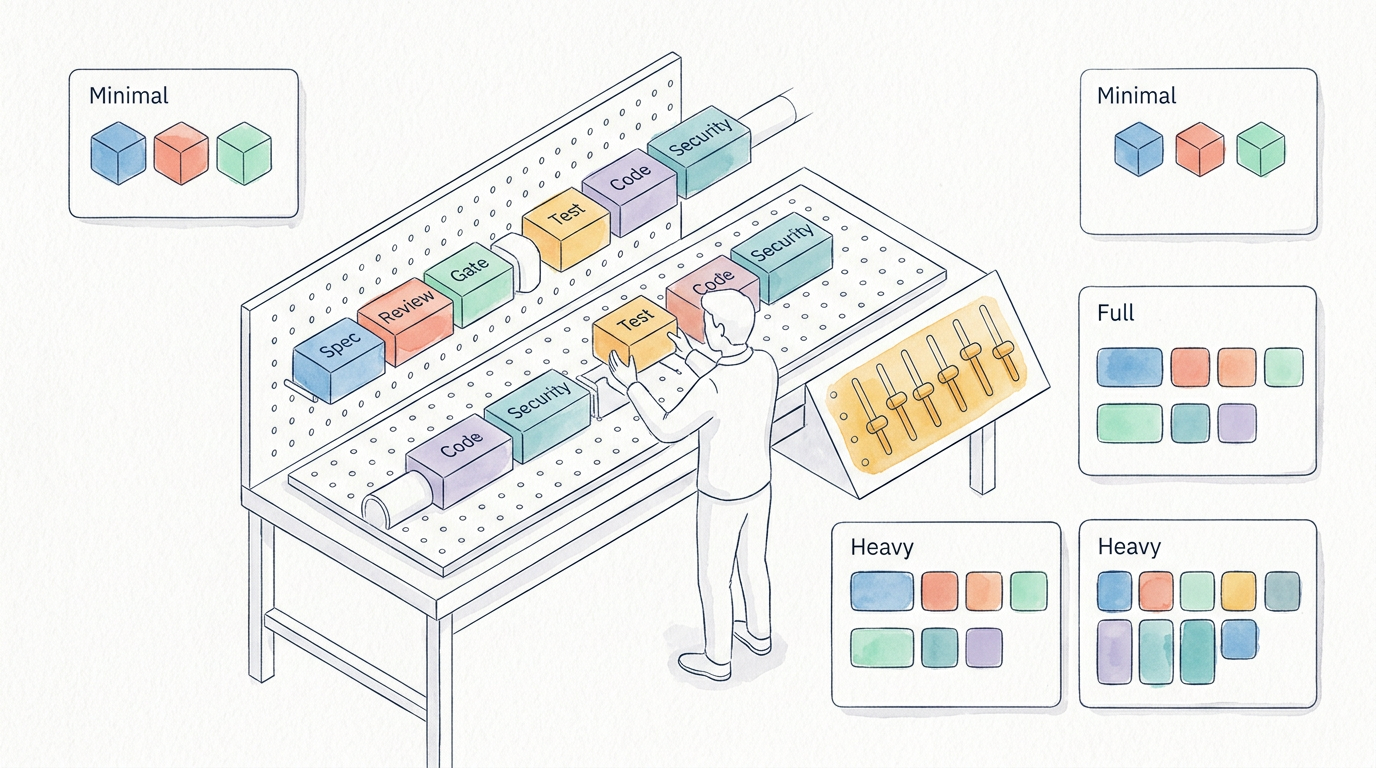
Selects rigor profile per task. Defines when to use lightweight vs. full review. Maintains profile library.
Adjusts review depth, retry limits, and quality thresholds based on the active profile. A proof-of-concept gets 2 review passes; a production feature gets 6.
Rigor profiles in practice
Fast validation of an idea. Minimal ceremony.
| Review passes | 1 |
| Max retries | 2 |
| Spec gate | Informal |
| Implementation review | Basic |
Ship-ready but not hardened. Good enough for first users.
| Review passes | 2 |
| Max retries | 3 |
| Spec gate | Lightweight |
| Implementation review | Standard |
Default for team development. Full TDD cycle.
| Review passes | 3 |
| Max retries | 4 |
| Spec gate | Standard |
| Implementation review | Adversarial |
Cross-team dependencies. Higher accountability.
| Review passes | 4 |
| Max retries | 5 |
| Spec gate | Formal + inquisitor |
| Implementation review | Adversarial + cross-review |
Customer-facing production. Zero tolerance for regressions.
| Review passes | 5 |
| Max retries | 5 |
| Spec gate | Formal + inquisitor |
| Implementation review | Multi-pass adversarial |
Regulated, safety-critical, or high-stakes. Maximum rigor.
| Review passes | 6 |
| Max retries | 6 |
| Spec gate | Formal + inquisitor + external |
| Implementation review | Multi-pass + human gate |
Automated: profile selection can be manual or rule-based. Pipeline execution adapts automatically.
Self-Improving Pipeline
The pipeline learns from its own failure modes.
Reviews pipeline metrics. Identifies recurring failure patterns. Updates prompts, thresholds, and review criteria based on data.
Tracks failure rates per phase, common remediation patterns, and review rejection reasons. Surfaces optimization opportunities. Pipeline improves between runs, not just within them.
Automated: metrics collection, pattern detection, threshold adjustment. Manual: prompt refinement, architectural changes.
Pipeline Factory
New pipelines are themselves pipeline output.
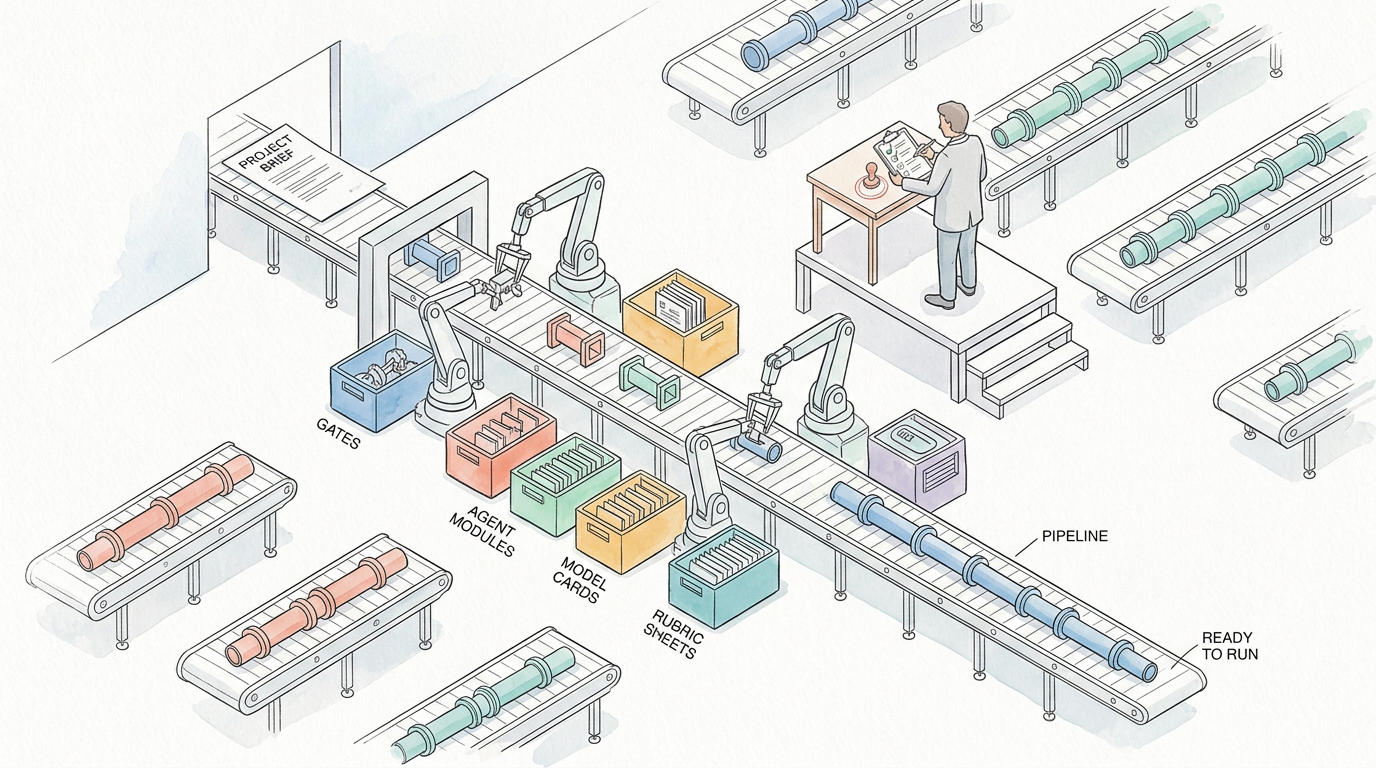
Specifies pipeline requirements. Reviews generated pipeline configuration. Validates against organizational standards.
Generates new pipeline configurations from specifications. The same TDD discipline that produces application code now produces pipeline infrastructure. Pipelines are testable, reviewable artifacts.
Automated: pipeline generation, configuration validation, integration testing. Manual: requirements, architectural review.
Patterns from pipeline operation
Brute-force retry loops are not pipelines
A common misconception: “just re-run the failing step until it passes.” This produces code that satisfies tests by accident, not by design. A pipeline adds structure at every transition:
Tests are harder than code
Approximately half of pipeline remediation cycles are triggered by test quality, not implementation quality. Writing good tests — tests that verify behavior rather than implementation — is the hardest part of automated development. This is why the red phase (test generation) has its own review gate, separate from the green phase (implementation).
// NEXT_STEP
Ready to design your team's next stage?
Whether you’re stuck at Stage 3 or scaling an existing pipeline, we can help you design the architecture for your next level of AI-assisted development.
Complimentary 30-minute technical assessment. No commitments.